SQL로 데이터 분석을 하다보면, 은근히 Group by 집계 쿼리문과 Having 후 필터링 조건문을 사용할 일이 많단 말이죠.
독자분들이 저와 같은 귀차니즘이라면 한 번 사용해보세요.
특히 pk가 논리적 erd로만 표현되어 있고, 물리적으로 생성되지 않아,
중복 데이터 유무를 조회해야 할 때 유용하게 사용 중입니다.
※ 지원 가능한 버전(Supported Versions): Current (17) / 16 / 15 / 14 / 13
1. Create Function
함수를 생성합니다.물론 group by문으로 조회할 테이블과 같은 데이터베이스에 생성해야 합니다.
group by 컬럼이 1개 이상이므로 jsonb 타입으로 집계처리 합니다.
create or replace function public.dynamic_group_by(
schema_name text,
table_name text,
group_by_columns text[]
) returns table (group_value jsonb , count_value bigint) as $$
declare
query TEXT;
group_by_cols TEXT;
begin
-- GROUP BY 컬럼 문자열 생성
group_by_cols := array_to_string(group_by_columns, ', ');
-- created dynamic query
query := format('SELECT json_build_object(%s)::JSONB AS group_value, COUNT(*) AS count_value
FROM %I.%I
GROUP BY %s',
array_to_string(
ARRAY(SELECT format('''%s'', %I', col, col) FROM unnest(group_by_columns) AS col),
', '
),
schema_name,
table_name,
group_by_cols
);
-- execute dynamic query & return result
return Query execute query;
end;
$$ language plpgsql;2. Create Sample Table
CREATE TABLE my_schema.sample_table (
category TEXT,
sub_category TEXT,
value INT
);
INSERT INTO my_schema.sample_table VALUES
('A', 'X', 10),
('A', 'X', 20),
('A', 'Y', 30),
('B', 'X', 40),
('B', 'Y', 50);
3. Use Function
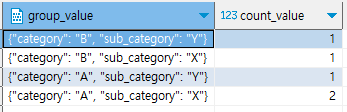
3-1. return group by
category, sub_category 컬럼 기준으로 group by 결과를 return 받습니다.
select *
from public.dynamic_group_by('my_schema','test_table',array['category','sub_category'])
;
[result]
3-2. return group by having
중복 데이터 유무를 체크할 때 자주 쓰는 Having 구문을 결과 값이 동일하게 아래와 같이 조회해보시면 됩니다.
select *
from public.dynamic_group_by('my_schema','test_table',array['category','sub_category'])
where count_value >1
;
'데이터베이스 > PostgreSQL' 카테고리의 다른 글
| [PostgreSQL] 인덱스를 활용한 효율적인 페이징 처리 (0) | 2025.06.03 |
|---|---|
| [PostgreSQL] 통계 정보 수집 (ANALYZE, VACCUM) (0) | 2025.01.03 |
| [PostgreSQL] count 함수를 쓰지 않고, 테이블 건수 조회하는 방법 (0) | 2025.01.03 |
| [PostgreSQL] 비정형 데이터를 PostgreSQL에 저장하고 정형 테이블로 변환하기 (1) | 2024.11.09 |
| [PostgreSQL] 모든 테이블 read only User / role 권한 부여 (0) | 2024.08.16 |



